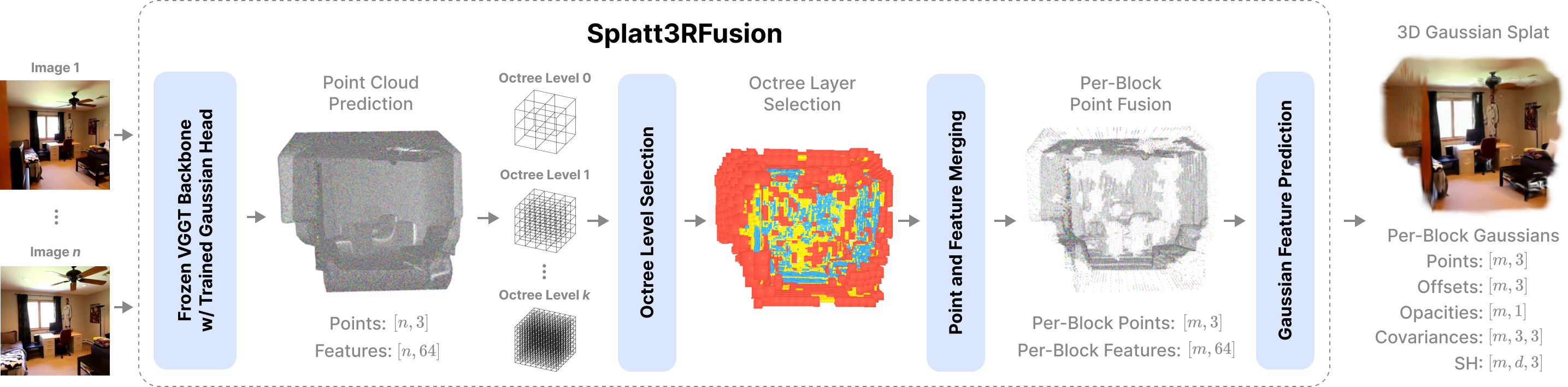
We present Splatt3RFusion, a feed-forward neural network that, given a set of unposed and uncalibrated images, directly reconstructs a compact and high-quality 3D Gaussian Splat representation of a scene. Unlike prior pixel-aligned feed-forward methods that typically predict one 3D Gaussian primitive per pixel in each image – producing severe redundancy, duplication, and ghosting on one physical surface – our approach efficiently fuses points in 3D space through a multi-scale octree structure, yielding a compact and coherent representation. Built upon VGGT, a foundation model for pose-free 3D geometry prediction, Splatt3RFusion introduces a Gaussian prediction branch that infers primitive parameters using only photometric supervision. We also introduce the ability to control the number of 3D Gaussians generated at test-time, allowing for a controllable tradeoff between PSNR and the number of 3D Gaussian primitives used. The model is efficient, reducing both memory usage and rendering cost, while achieving state-of-the-art results on RealEstate10k and ScanNet++.
Unlike prior approaches that generate a redundant Gaussian primitive for every pixel, Splatt3RFusion merges 3D points in feature space using a multi-scale octree, resulting in a much smaller set of non-pixel-aligned Gaussians. Our approach extends a pretrained VGGT model by introducing a new Gaussian Feature Head, which predicts feature vectors for each pixel. These features, along with 3D points from VGGT, are merged in the octree based on feature similarity, with the subdivision level determined by the cosine similarity of matching features. Within each octree cell, we average the 3D positions and feature vectors, and then use a two-layer MLP to predict the final Gaussian parameters for each merged point.
By utilizing an octree, Splatt3RFusion has a dynamically varying spatial resolution, assigning more points to detailed regions and reducing redundancy in overlapping views. We train our model end-to-end using only rendering losses, combining mean squared error and perceptual (LPIPS) losses between rendered and ground truth images. Training is performed in two stages: we first supervise reconstructions from context camera views, and then incorporate target views with optimized camera poses. In addition to supervising our multi-layer octree selection, we supervise each layer of our predicted octree structured layer separately. This enables Splatt3RFusion to learn compact, generalizable 3D representations that support high-quality novel view synthesis.


@article{smart2024splatt3r,
title={Splatt3RFusion: Learning Compact 3D Gaussians via Feed-Forward Point Fusions},
author={Brandon Smart and Chuanxia Zheng and Iro Laina and Victor Adrian Prisacariu},
year={2024},
eprint={2408.13912},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2408.13912},
}